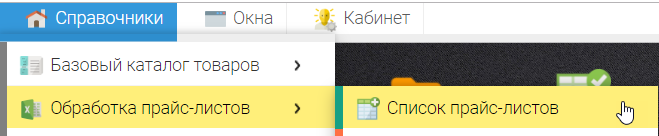
Przykłady selektorów (CSS, XPath) do pobierania danych ze stron sklepów internetowych (parsowanie stron).
Dostajemy artykuł producenta z listy wartości (tagi ul li)
Selektor CSS:
ul. desc-list li:nth-child(7)::text()

lub XPATH dla SKU:
//ul[li/text() = "Artykuł"]/span[2]/text()
.png "Przykłady selektorów CSS XPath do parsowania danych ze stron sklepów internetowych")
Pobierz artykuł producenta z tabeli atrybutów produktu (filtruj według nazwy atrybutu produktu)
Selektor XPath: //tr[td/text() = "Artykuł"]/td[2]/text()

Otrzymujemy cenę produktu (na podstawie id elementu, który zmienia się na każdej stronie z produktem)
Selektor XPath wyszukujący słowo „cena_detaliczna”: //span[contains(@id,"cena_detaliczna")]

Otrzymujemy listę linków do innych stron produktów (paginacja), poza bieżącą stroną (ponieważ na niej zostały już otrzymane linki do produktów)
Selektor CSS: ul. pagination li:not(. active) a

Lokalizatory CSS:
div#pocks — szukanie div o identyfikatorze równym pocks
div. perl - szukamy div, którego klasa nazywa się perl
body[vlink=1] — szukanie tagu body z atrybutem vlink=1
body[vlink*=1] — szukamy tagu body, w którym atrybut vlink zawiera jeden
body[vlink€=1] — szuka tagu body, którego atrybut vlink kończy się na jeden
body[vlink^=1] — szuka tagu body, którego atrybut vlink zaczyna się od jedynki
Przestrzeń znajduje wszystkich potomków elementu. Przykład:
div#ires a - znajduje wszystkie linki z div o identyfikatorze ires
div#ires a:nth-of-type(1) - najpierw znajduje wszystkie linki z div o identyfikatorze ires
div >a - wszystkie div, które mają dziecko zaraz po nich a
div+div - znajduje div, który pojawia się zaraz po pierwszym div
div+a - wszystkie div, po których następuje element (linki)
div ~ div - pomiń element po elemencie
a:contains("ggdgdgd") - znajduje a
*. warning - dowolny element z klasą ostrzeżenia
div * p - szukamy elementu p, który ma przodka div i mogą być między nimi elementy
h1. opener+h2 — poszukaj sąsiada elementu h2, przed którym element h1 ma klasę opener
a[rel~="copyring"] - szukamy linku z atrybutem rel, który ma wewnątrz klasę z wartością copyring
span[hello='Cleveland'][goodbye='Columbus'] — szuka elementu span z atrybutem hello ustawionym na Cleveland i atrybutem goodbye ustawionym na Columbus
div. flyout > a — znajdź wszystkie linki znajdujące się bezpośrednio za elementem div z klasą flyout
div#action_list_body_current li:nth-of-type(1) — Znajdź drugie zadanie na bieżącej liście
#quick search a[accesskey ="p"] — Znajdź drugi obraz z atrybutem accesskey "p" w szybkim wyszukiwaniu
#context_list a:contains('line') — znajdź kontekst w tabeli Contexts, który zawiera tekst „line”
Lokalizatory XPath:
/body/. . - rodzic tagu html badi, tobish
Jaka jest różnica między xpath a css, w xspace możemy przechodzić od dołu do góry, a w css tylko od góry do dołu. //
//a[text()='jakaś wartość'] — znajdź link z tekstem jakiejś wartości
author[last-name [position()=1]= "Bob"] - znajdź element autora, który ma element nazwisko i nazwisko jest pierwszą pozycją
//div[@id='header'] — element div z nagłówkiem id
//div[1] - pierwszy div
//div[position()=1] to to samo co //div[1]
//div[2 i 3] - druga i trzecia dywizja
W xpath relacje elementów definiują osie
// - oznacza, że szukamy wszystkich zagnieżdżonych elementów
/descendant:div[@id='header'] - znajduje wszystkich potomków div z nagłówkiem id
book/*/last-name - znajdujemy element buk po którym jest dowolny element i zaraz po nim pojawia się lastname element
*[@specialty] - dowolny element z atrybutem specialty
author[first-name][3] to element o nazwie author, który ma element potomny imienia i jest trzecim
autor[nie(stopień lub dyplom) i publikacja] - znajdź element autora, który nie ma dziecka stopnia lub dyplomu, ale ma element publikacji
ancestor::author[parent::book][1] — znajdź przodka, który ma nazwę autora elementu i który ma niepodrzędną książkę nadrzędną i wybierz pierwszą pozycję
//a[text() ="Preferences"][ancestor::*[@id='header']] — znajdź link Preferencje w górnym menu (przejdź od góry do dołu, najpierw napisz link z tekstem Preferencje
//*[@id ='action_list_current']//span[@class='next_action_name'][following-sibling::*/a[contains(@href,'contexts') and text() ='Offline'] ] - Znajdź wszystkie zadania na bieżącej liście w kontekście offline
Czerpanie korzyści ze stylu
substring-before(substring-after(//div[@class="Header"]/div[@class="Header-jpeg"]/@style, "background-image: url("), ")")
Rozp. wyrażenie
\€\(". prod-img"\). css\("backgroundImage", "url\((. *?)\)
aby uzyskać link do obrazu z tekstu
€(. prod-img"). css("backgroundImage", "url(https://site.com/img/014/114288.jpg)");
Spinki do mankietów:
w3.org/TR/selektory/
w3schools.com/css/css_examples. asp
Ogólny opis analizy składni witryny .
Monitorowanie cen konkurencji w Internecie