Платформа для автоматизации бизнеса в 2024 году.
Создай интернет-магазин, синхронизируй товары и заказы на всех маркетплейсах, управляй бизнесом в единой системе, оптимизируй все рутинные процессы.



Облачное решение на базе CMS OpenCart с современным дизайном
Уникальные тексты для людей и SEO продвижения, экономь на рекламе
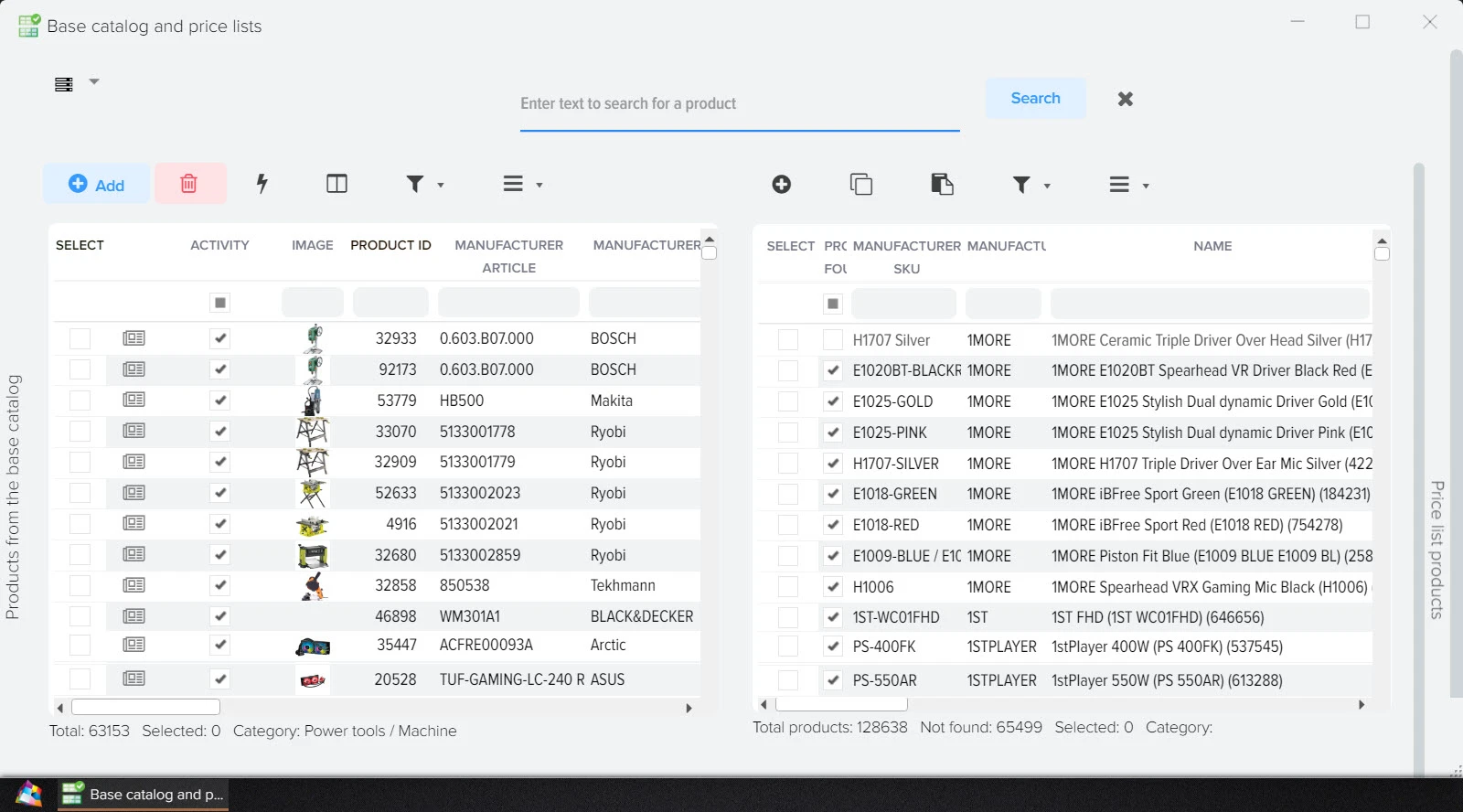
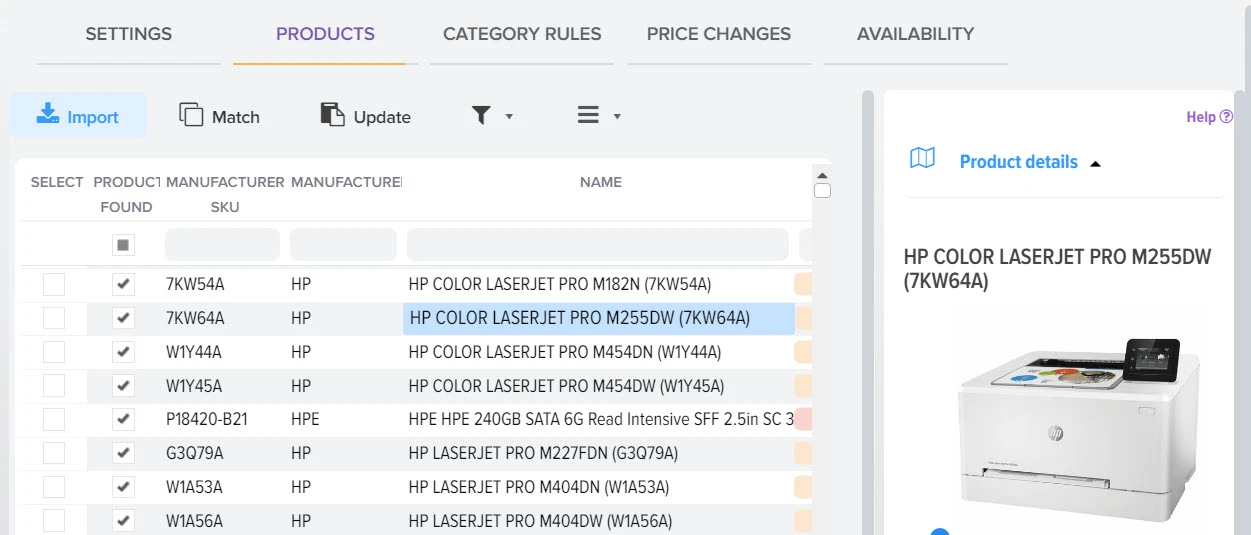
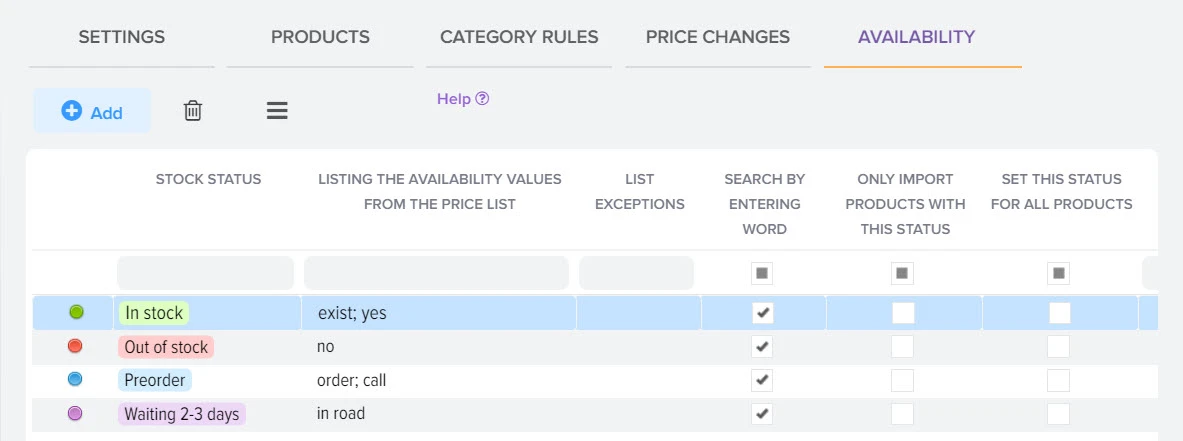
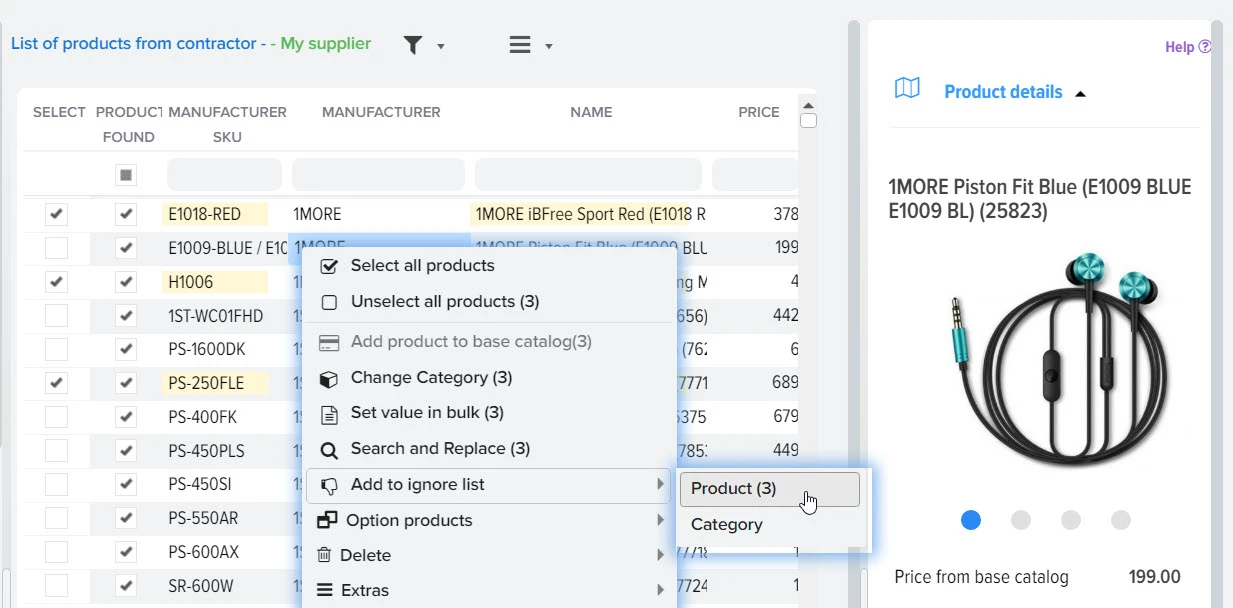
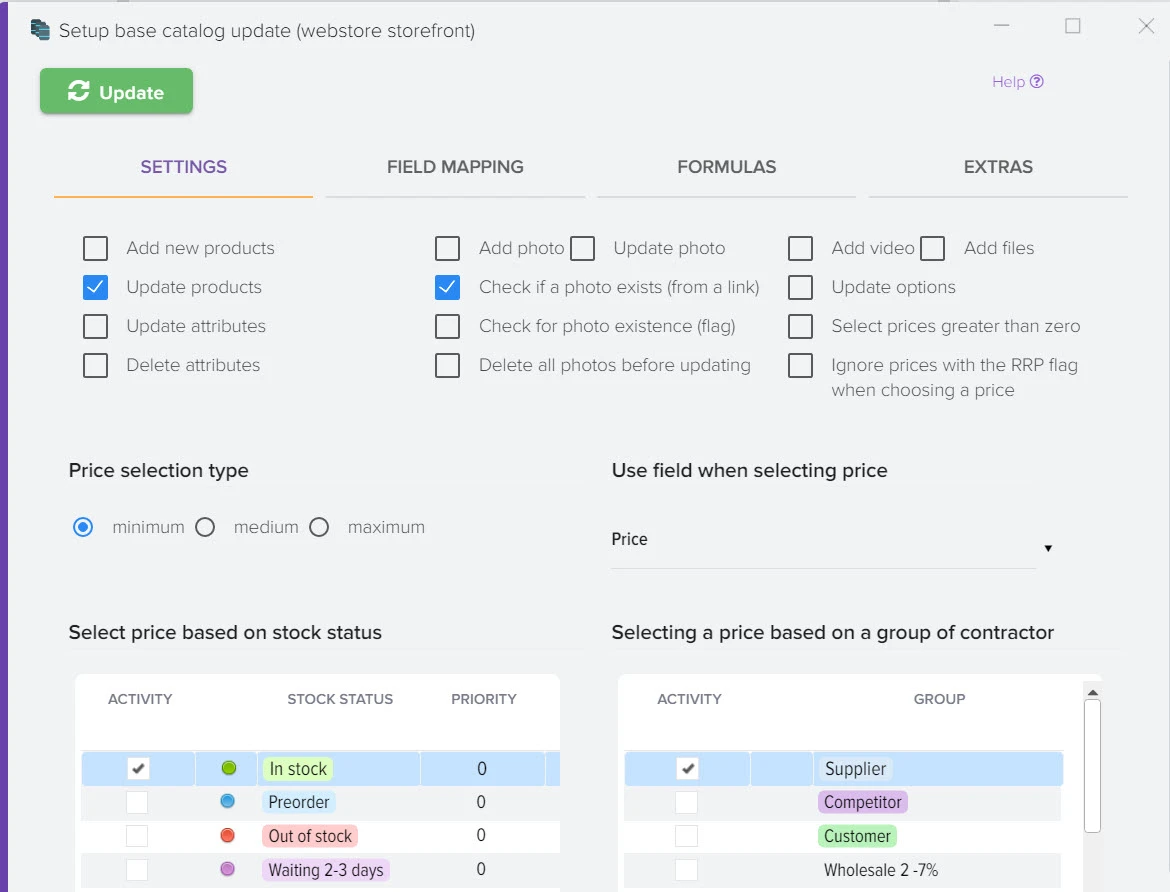
Автоматизированный контроль за ассортиментом поставщиков
Отслеживание и контроль цен на товары конкурентов для анализа рынка
Максимальное увеличение выбора товаров для покупателей
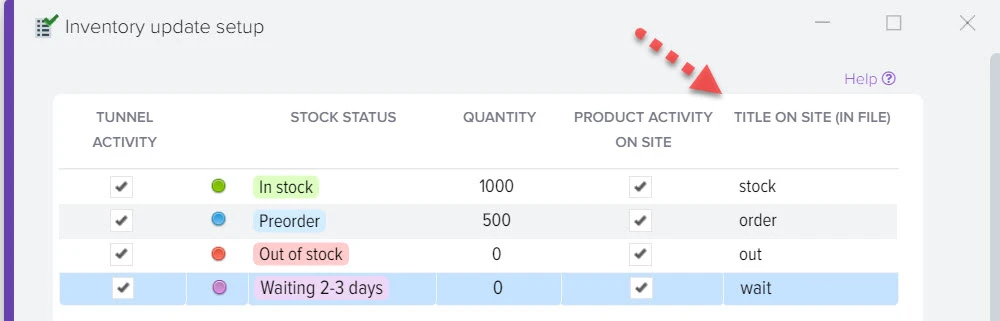
Создание фида с товарами, ценами и наличием для любых площадок
Быстрое добавление видео, фото, описаний и техн. характеристик
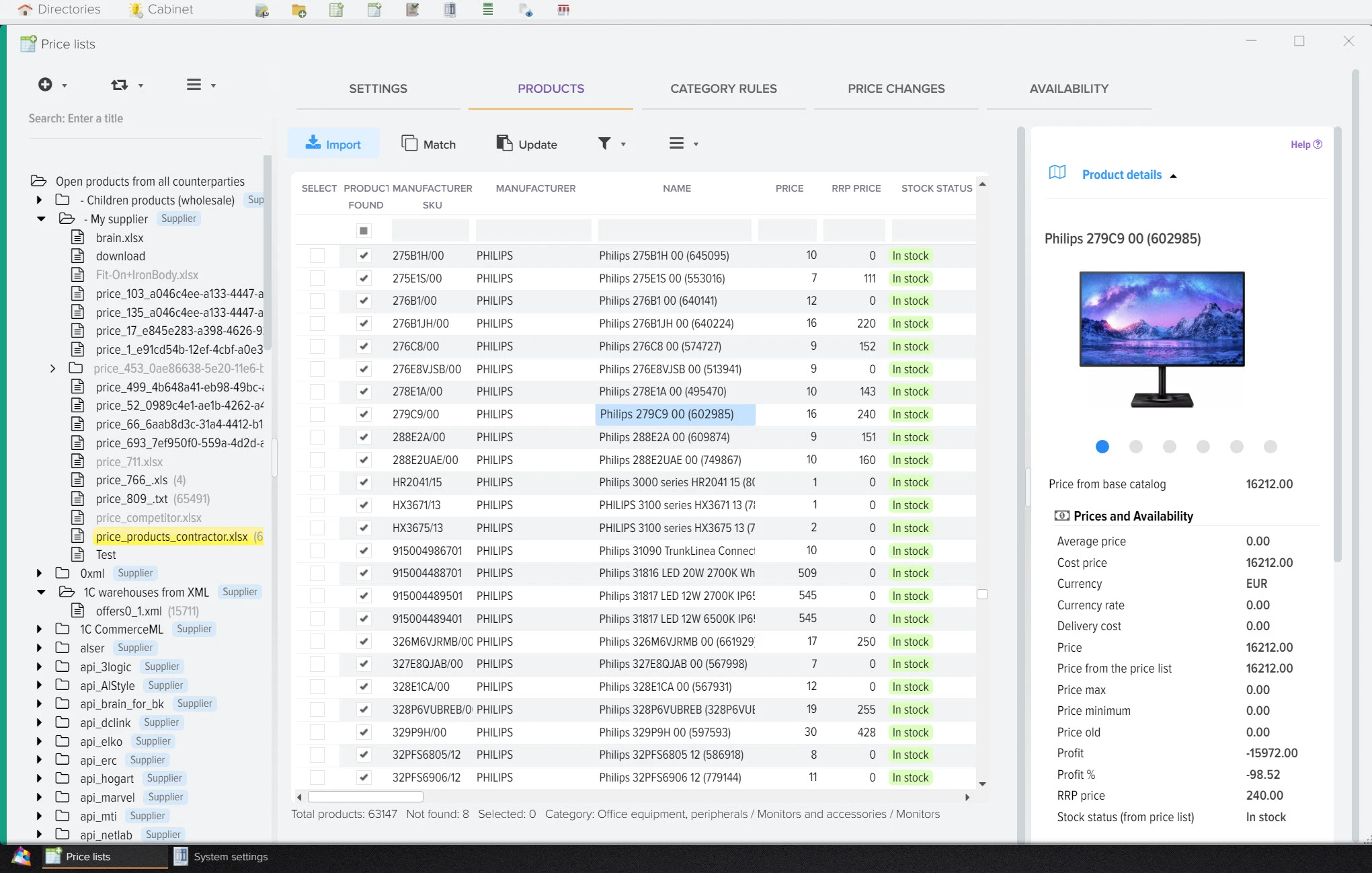
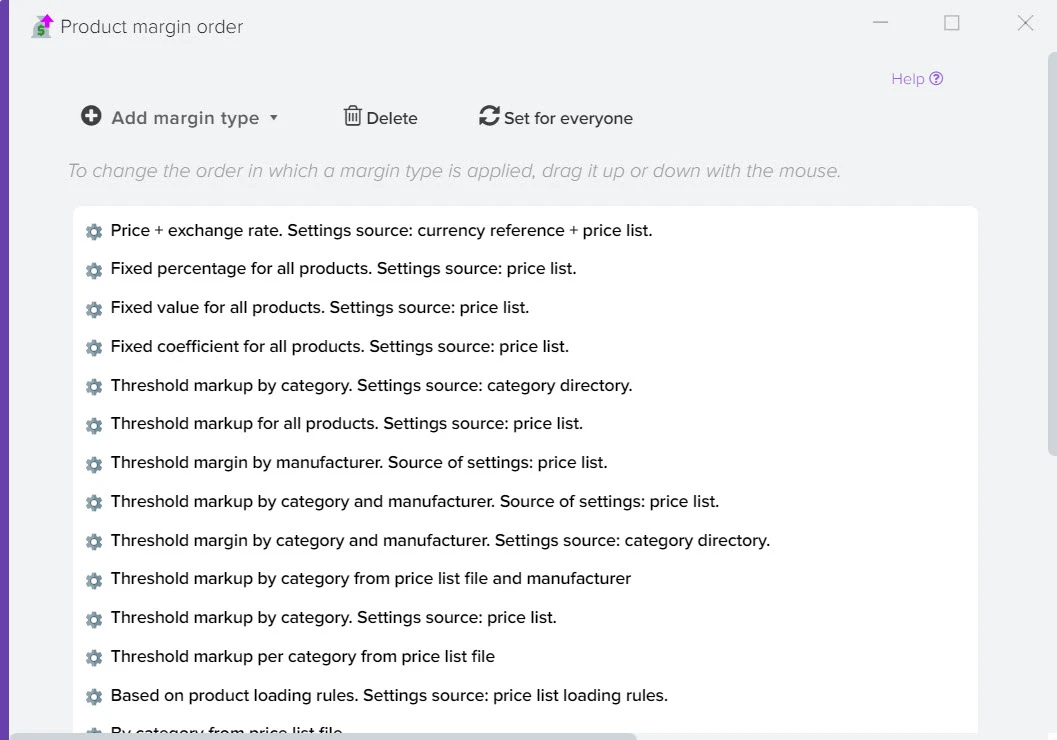
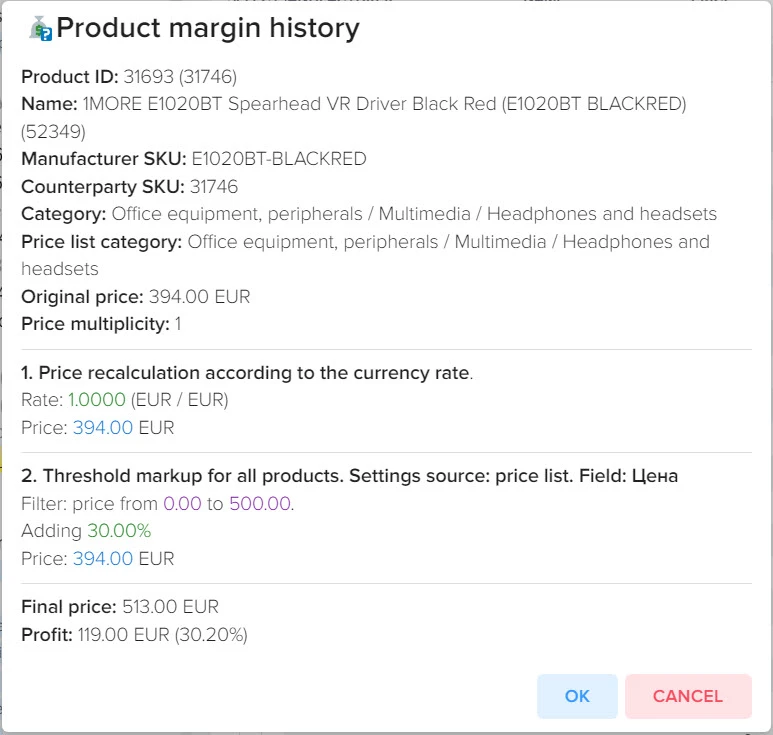
Анализ и управление ценами на товары от поставщиков.
Воспользуйся передовым решением,
пока конкуренты занимаются рутиной.



Используй облачную версию CMS OpenCart с современной дизайн-темой и готовыми модулями автоматизации. Уникальная возможность быстро создать элегантный и функциональный интернет-магазин без необходимости нанимать программистов и дизайнеров. Используй лучшее – забирай аудиторию конкурентов!
Начни свой путь к успеху с эксклюзивным дизайн шаблоном, который легко персонализировать под свой бренд всего за несколько простых шагов!
Интернет-магазин адаптивен к различным устройствам обеспечивая идеальное отображение для привлечения всех клиентов.
Готовые модули расширения позволяют создать интернет-магазин в соответствии с вашими требованиями, предоставляя клиентам максимальное удобство.
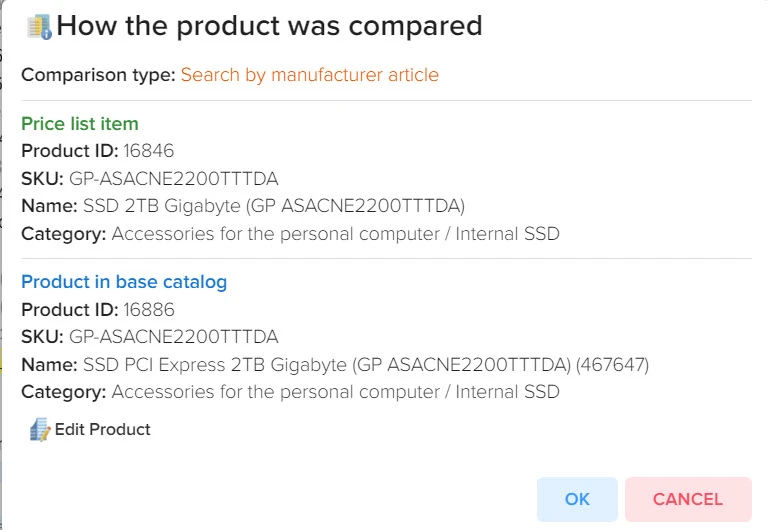
Эффективное сравнение прайсов и управления ассортиментом - ключевой момент в успешном развитии вашего бизнеса. Путём автоматической обработки прайсов программа оптимизирует ваш ассортимент товаров, находит оптимальные цены, которые будут привлекательны для клиентов и прибыльны для вас. Это не только помогает максимизировать прибыль, но и обеспечивает удовлетворение клиентов.
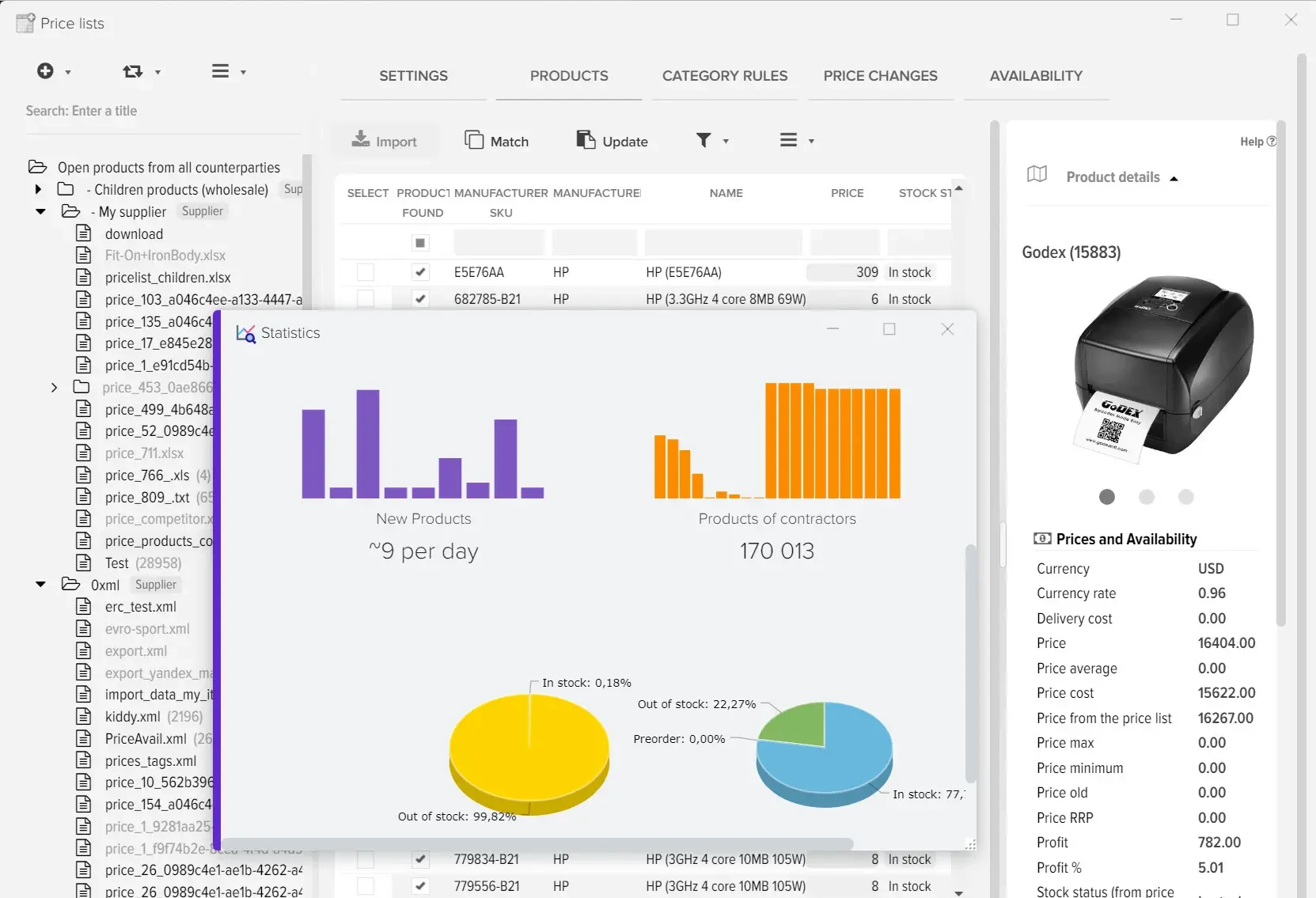
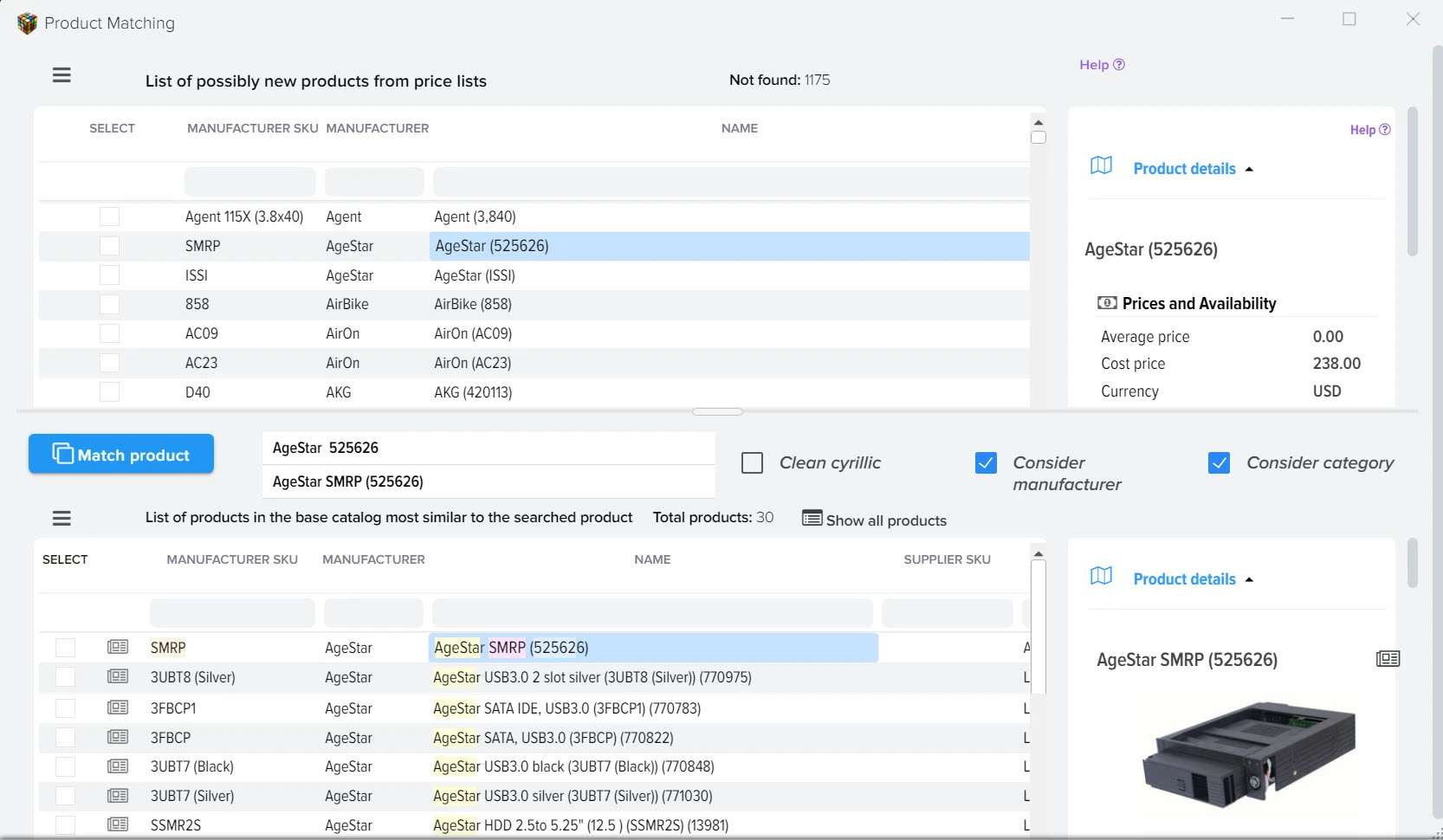
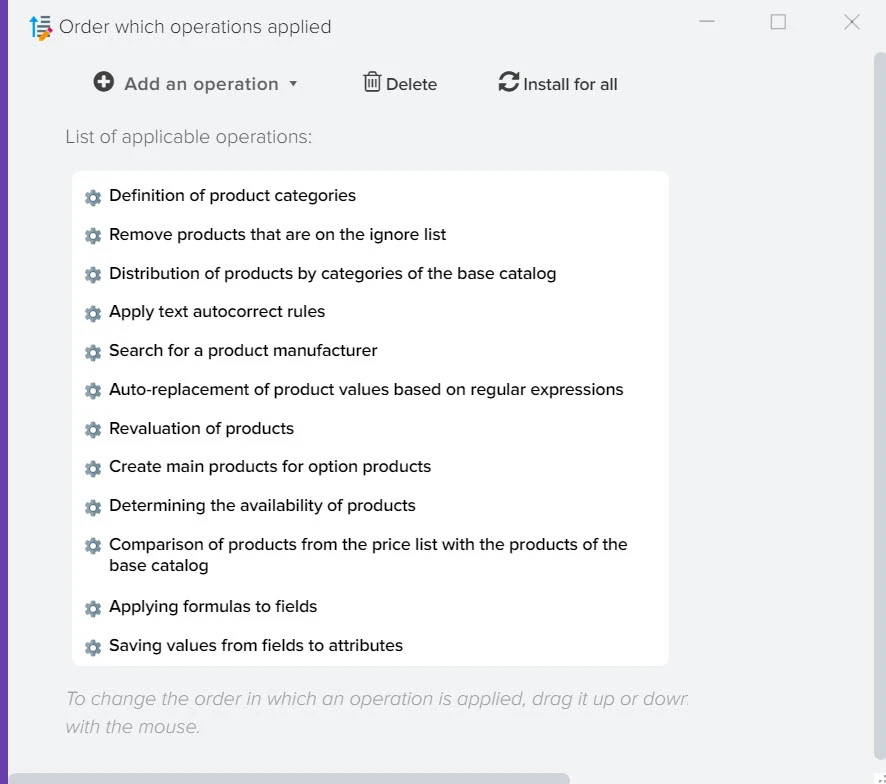
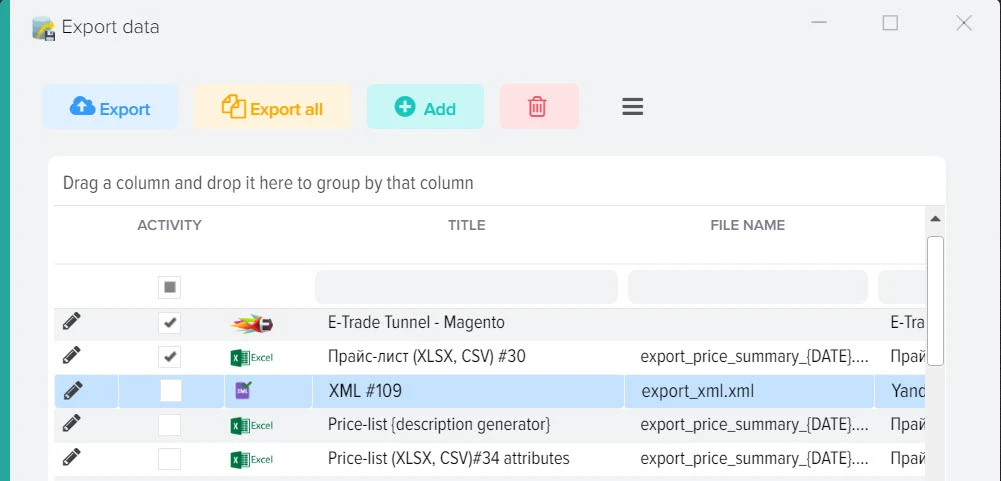
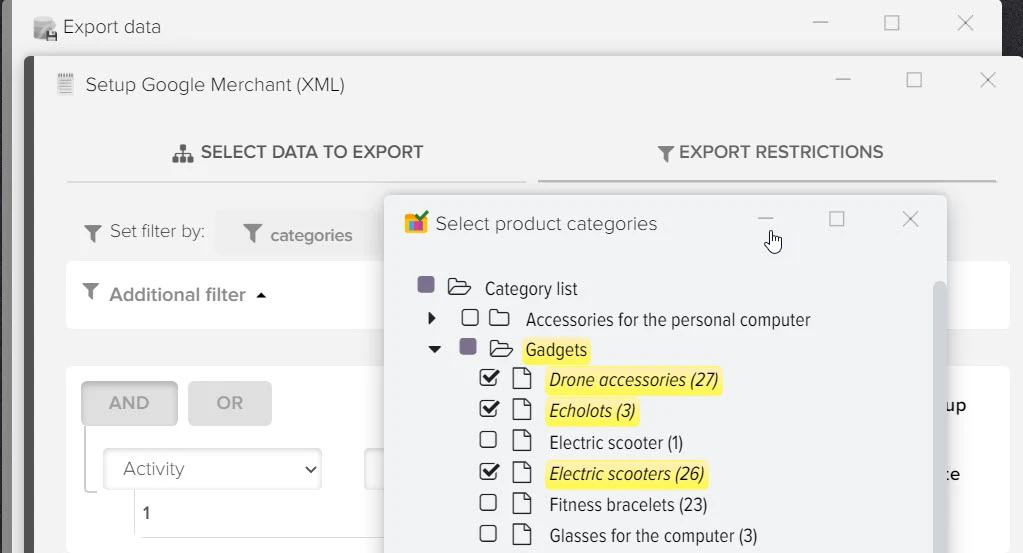
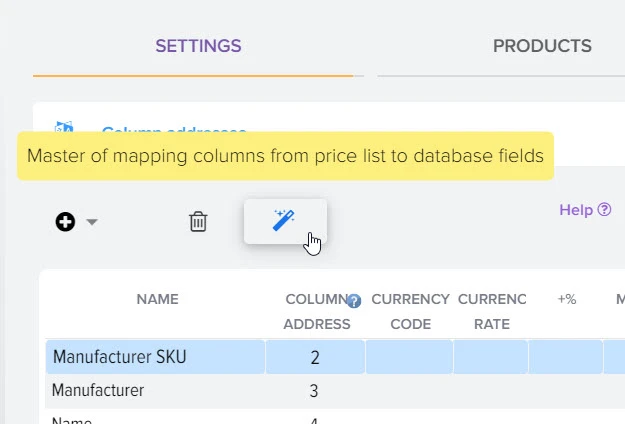
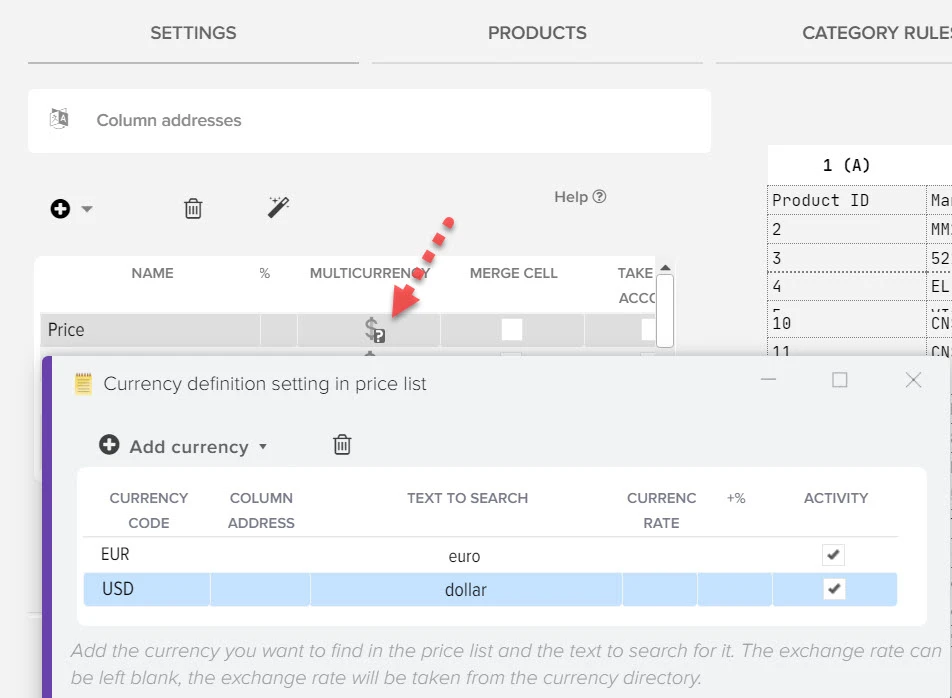
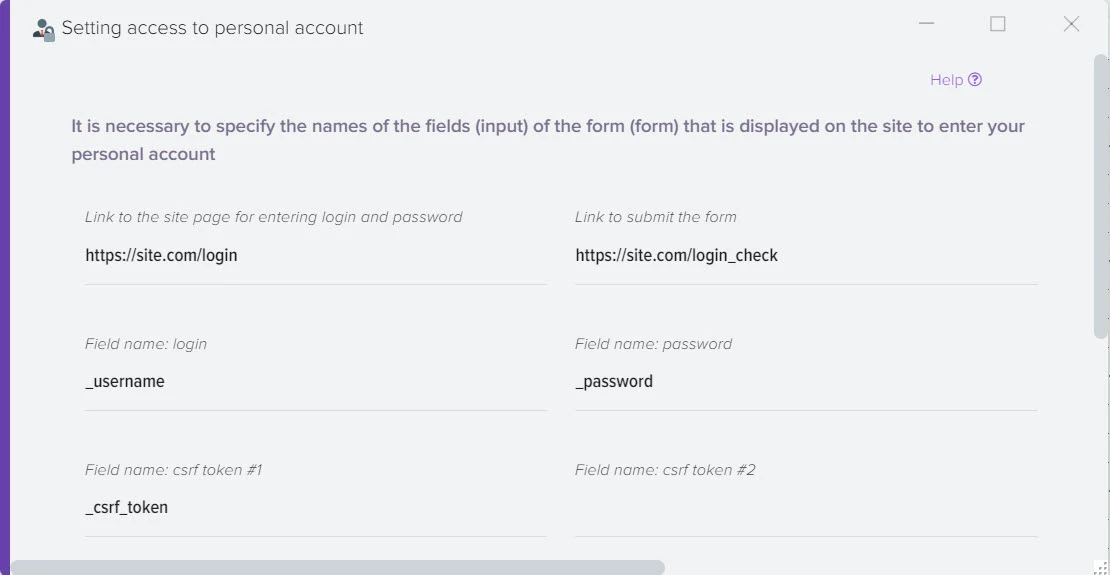
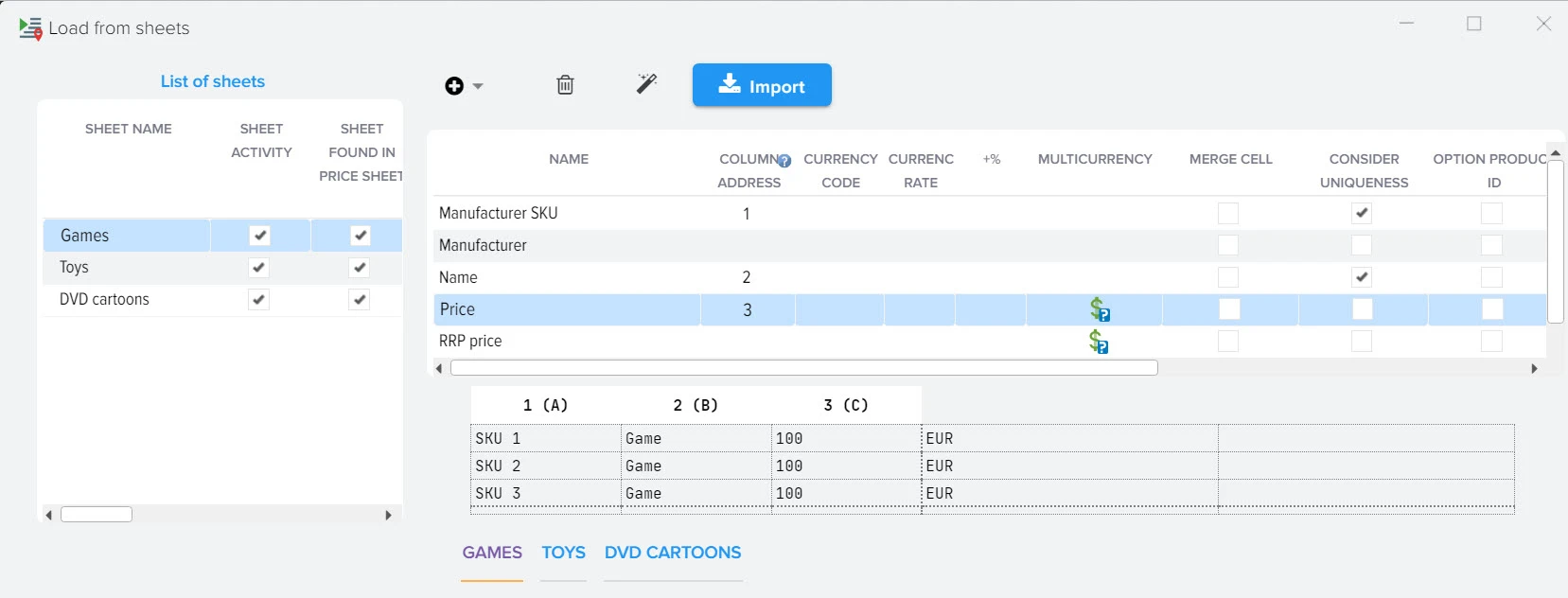
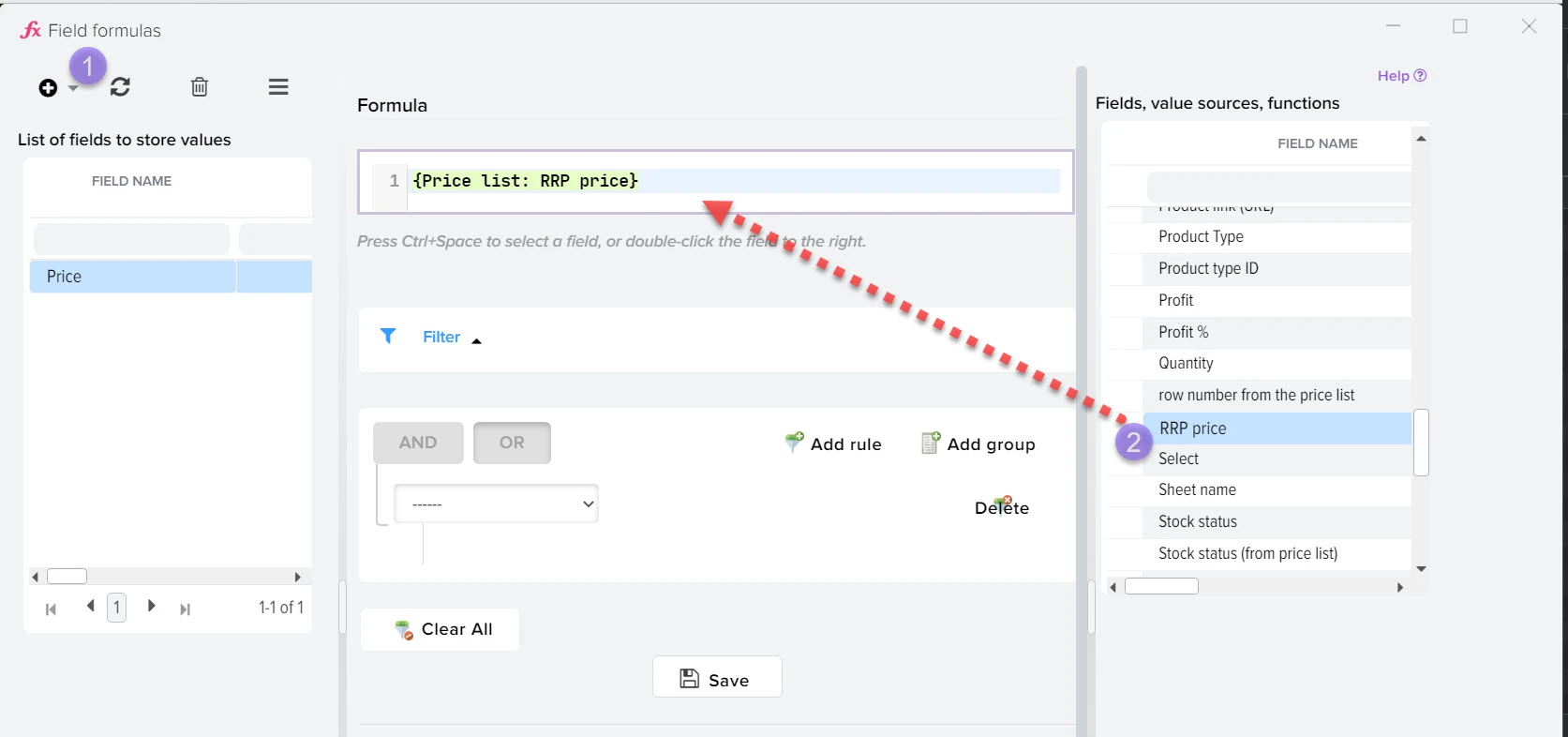
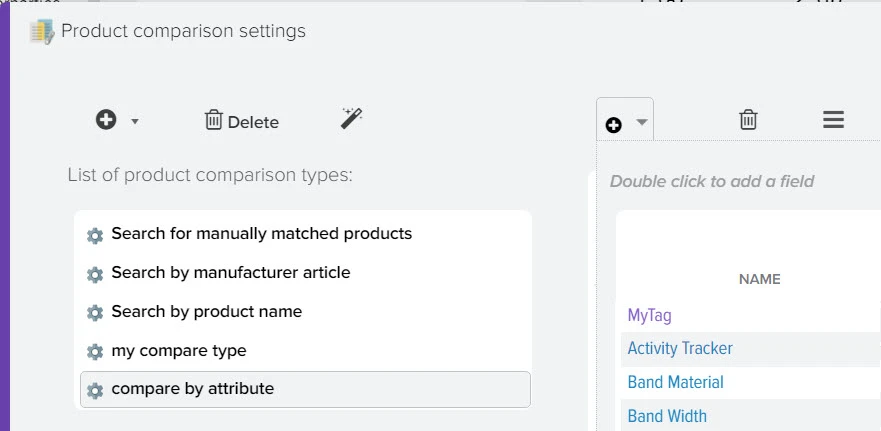
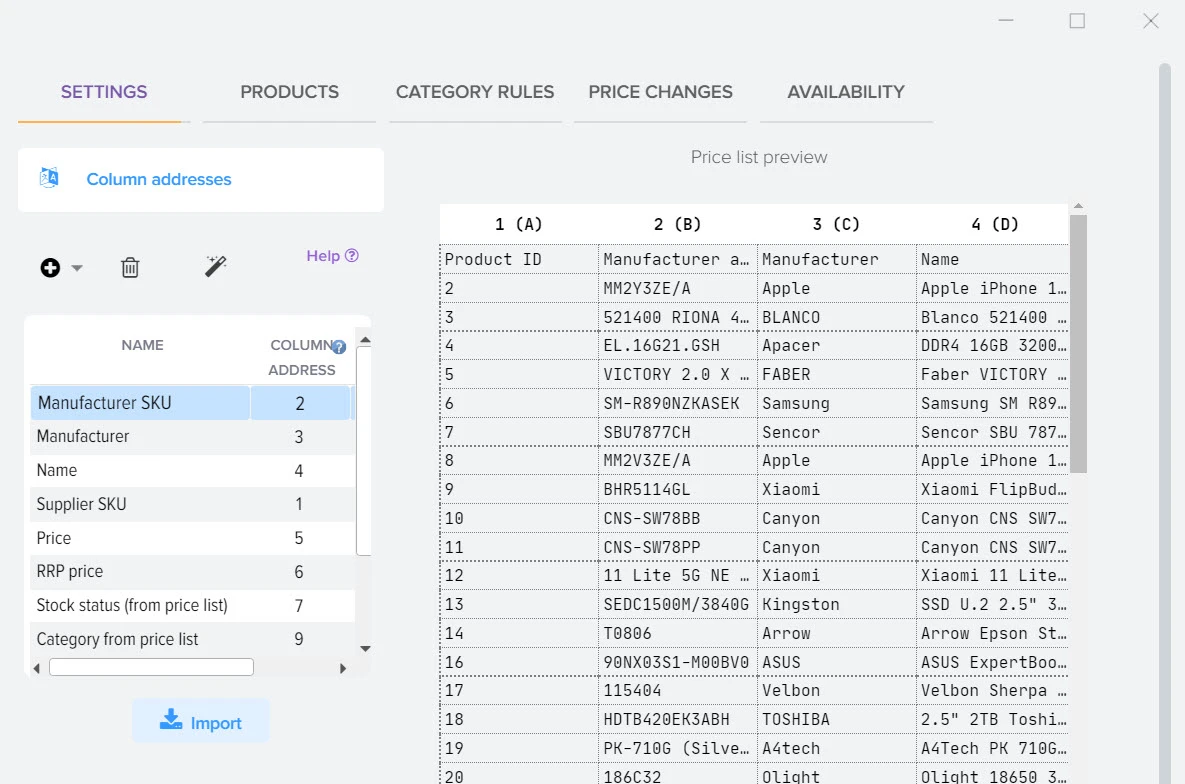
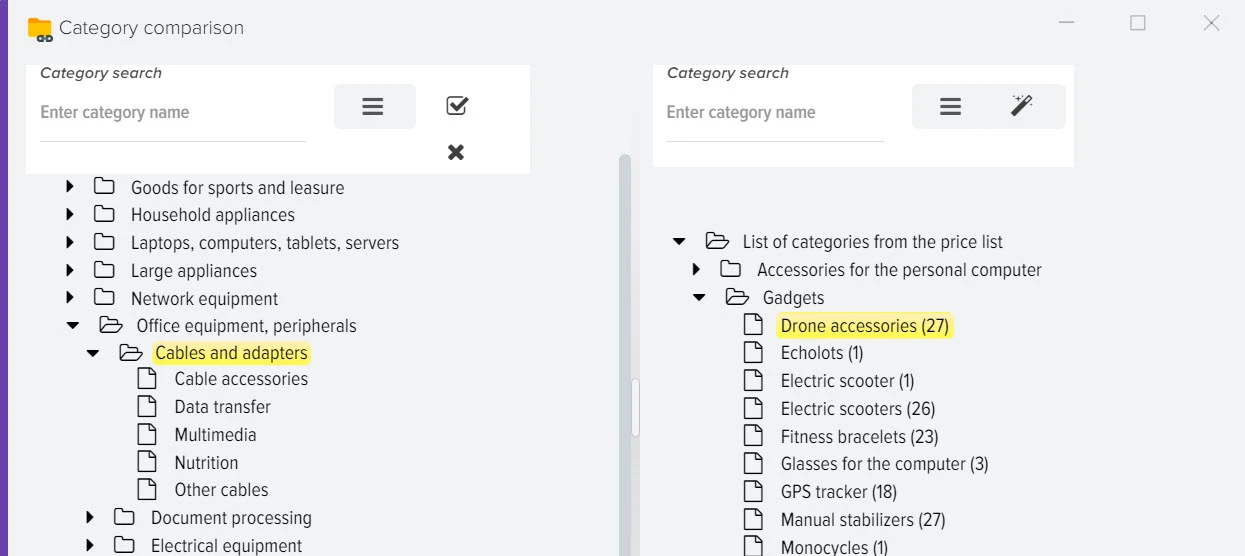


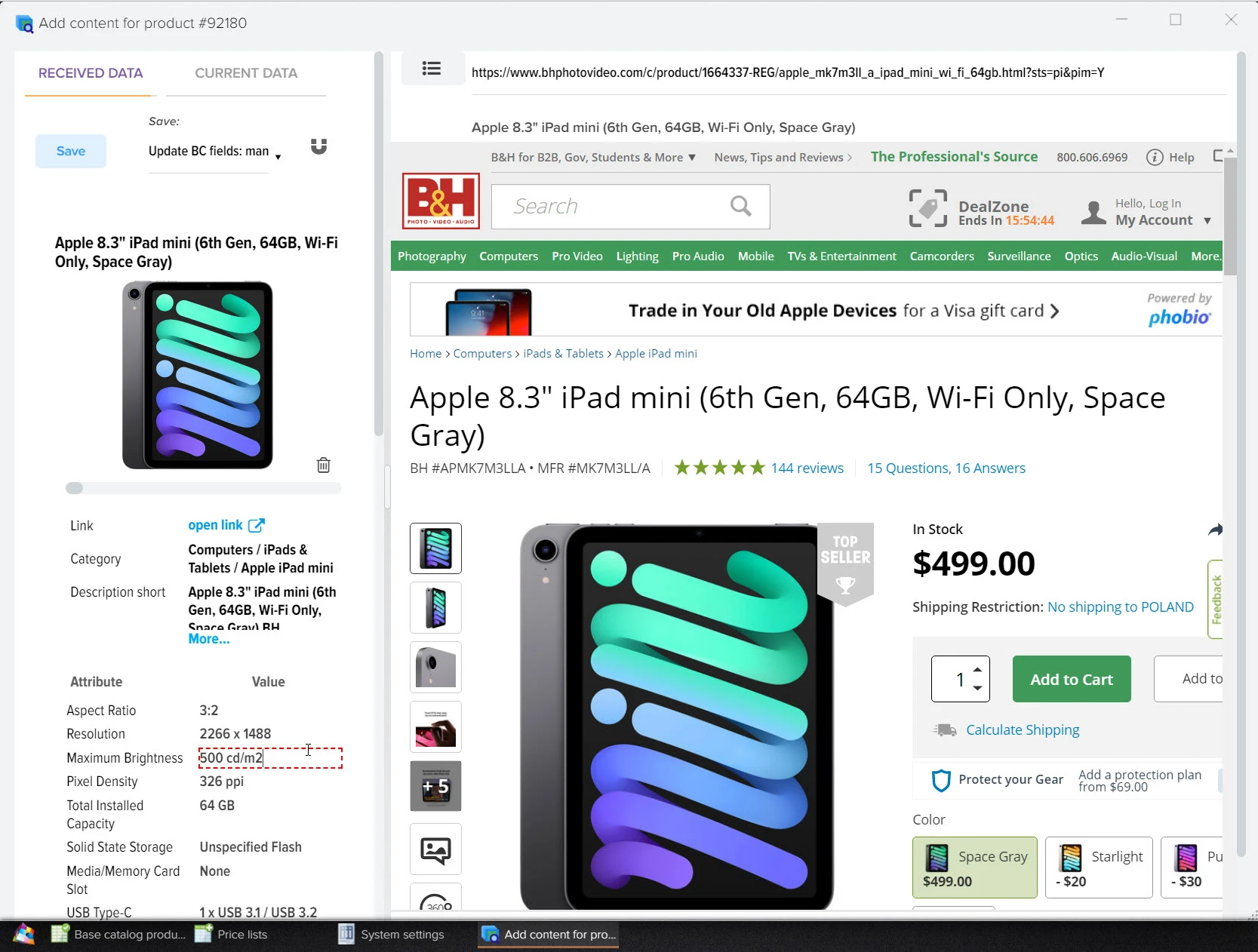
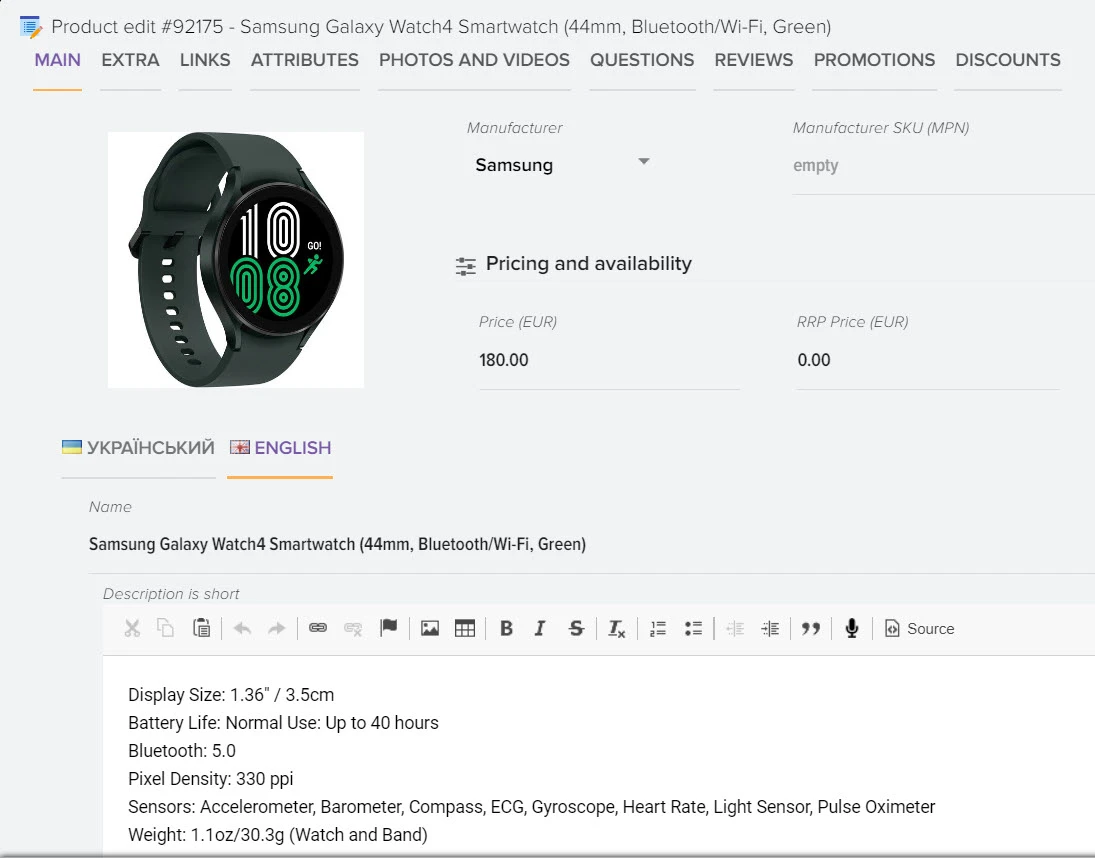
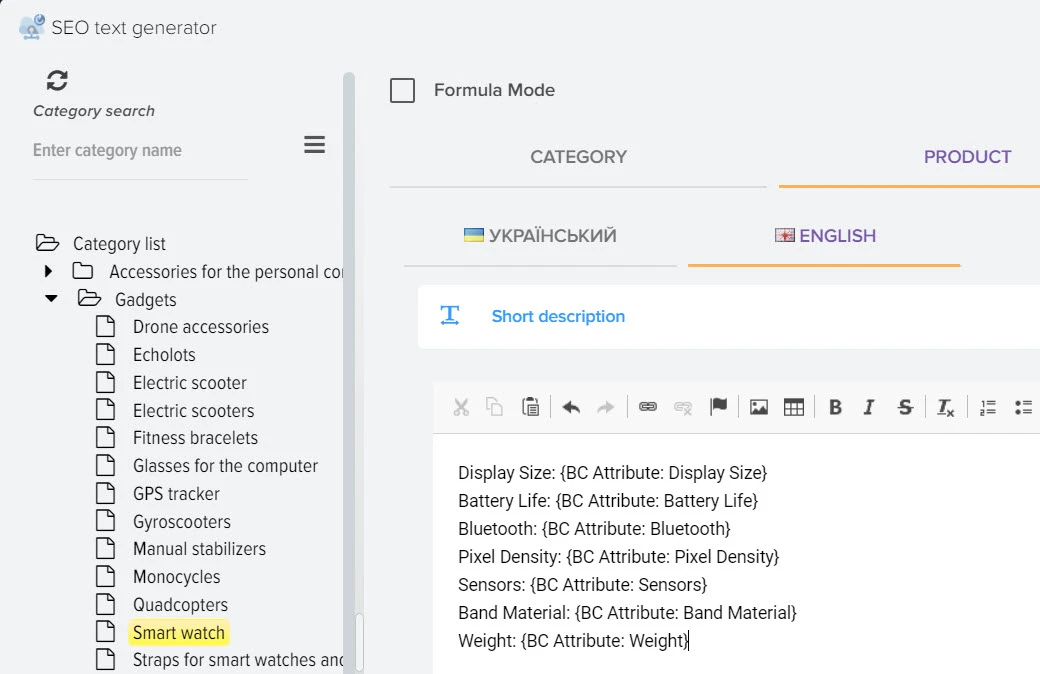
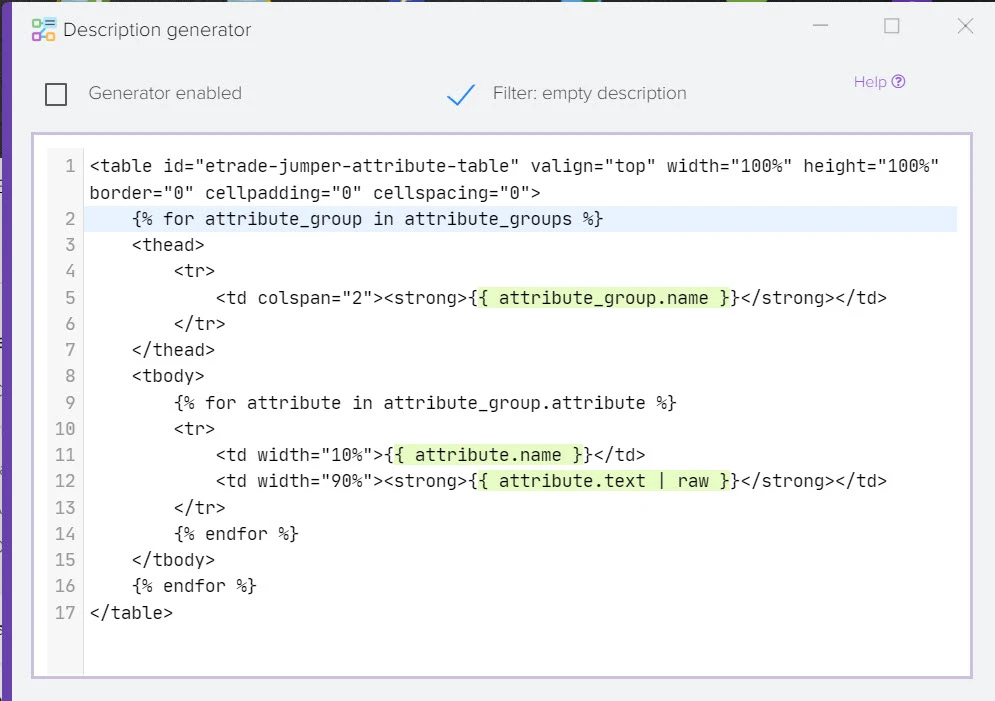
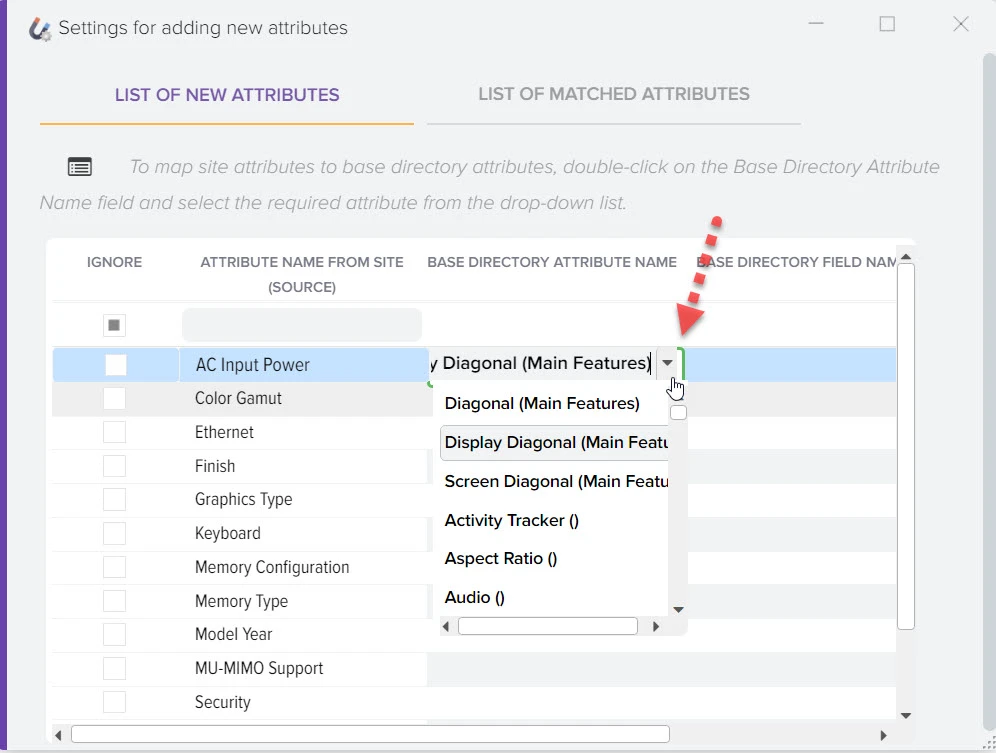
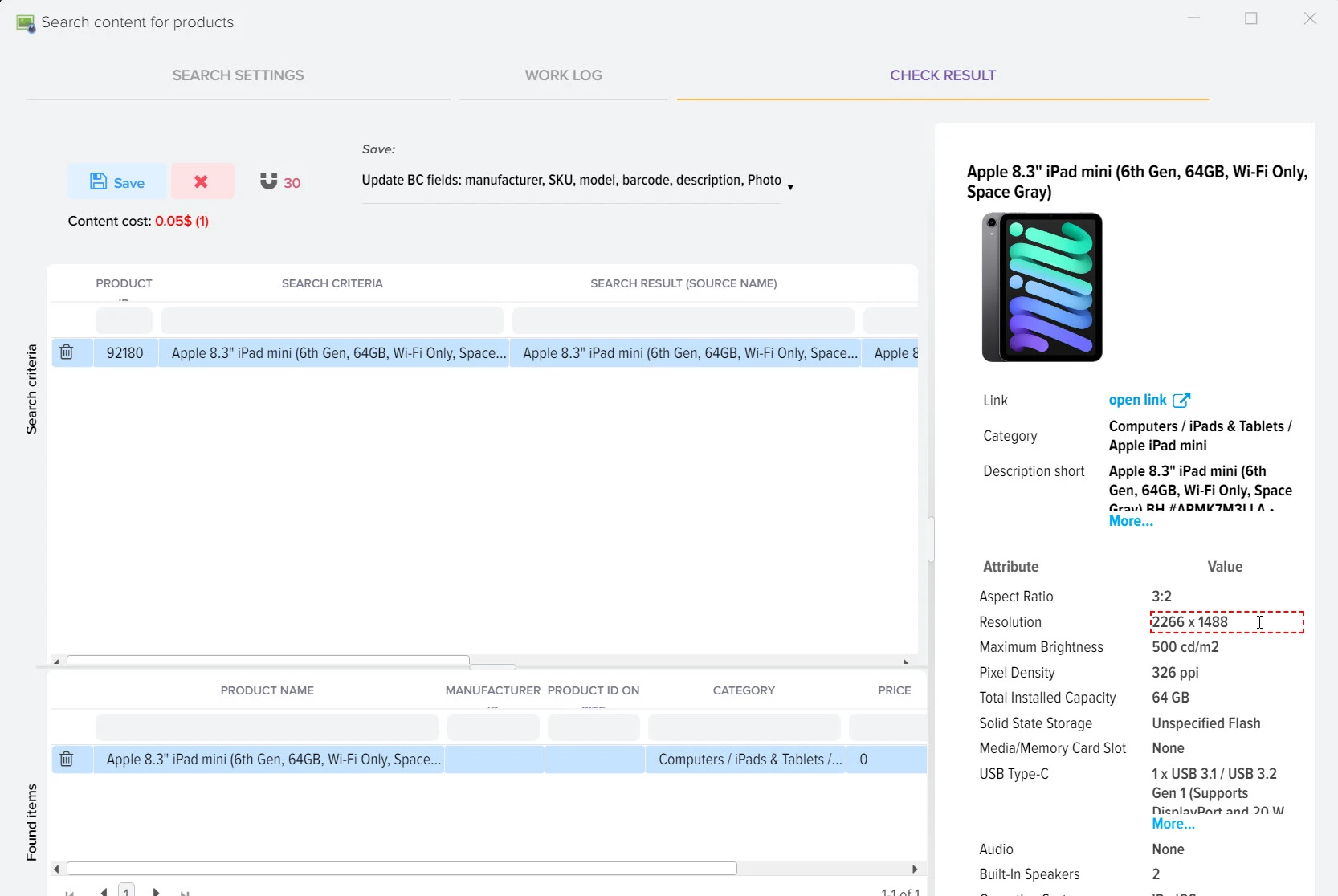
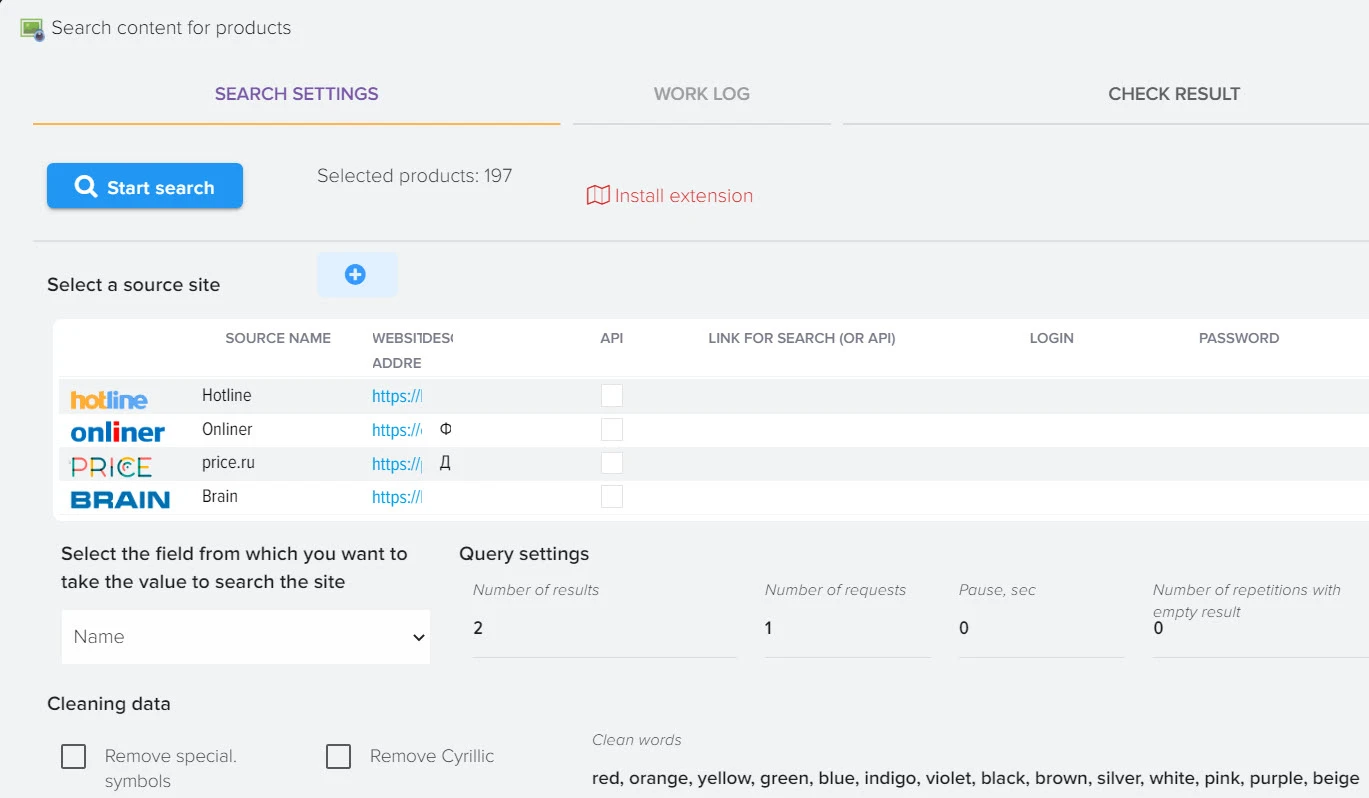
Наша платформа автоматизации – это инновационное решение, которое не только использует передовые технологии искусственного интеллекта для создания высококачественного контента, но также осуществляет поиск актуальной информации в реальном времени.
Мы обеспечиваем полный цикл работы: от генерации текстов и создания описаний товаров до формирования уникальных заголовков с учетом оптимизации для поисковых систем. Благодаря персонализации и разнообразию контента мы гарантируем, что ваша аудитория будет вовлечена и удовлетворена результатами.
С каждым годом потребители становятся все более требовательными. Какие методы персонализации используете вы? Elbuz предлагает инновационные инструменты для анализа данных о клиентах и создания индивидуальных предложений, учитывая их предпочтения и поведение.
Наши тарифы, позволяют новичкам начать бизнес с минимальным бюджетом.
А крупныи игрокам отказаться от других решений!
Присоединяйтесь к лидеру автоматизации интернет-магазинов.

"Это то, что я искала! Я в восторге, всё быстро, легко и поддержка помогла настроить, рекомендую Elbuz всем, кто хочет запустить успешный интернет-магазин.

Мне нравится как быстро я смогла создать интернет-магазин без головной боли. Шаблон выглядит супер, товары продаются как горячие пирожки.

Elbuz - просто космос! Я только начал использовать их программу для моего магазина и уже видны улучшения. Базовый шаблон - огонь!

Лучшее, что я использовал для своего магазина. Программа просто бомба! Рекомендую всем без сомнения!

Шаблон выглядит современно, но мне кажется, что некоторые модули недостаточно гибкие, но в целом удобно, особенно для тех, кто только начинает свой бизнес.

Я немного сомневалась в начале, но после использования их генератора текстов я убедилась - это то, что нужно! Мой магазин начал привлекать больше внимания!

Раньше тратила массу времени на обновление ассортимента и контроль цен. Теперь всё автоматизировано, парсинг сайтов и оповещения об изменениях - то, что мне действительно нужно.

Мне нравится как легко сравнивать цены поставщиков и контролировать наличие товара. Интеграция с поставщиками - просто бомба! Уже смотрю, как растет моя прибыль.

Я был скептичен в начале, но сейчас я просто в восторге, система автообновление цен - просто пушка! Спасибо за такой крутой продукт!

Elbuz - настоящий must-have для владельцев интернет-магазинов! Автоматизация сравнения цен и контроль наличия товара действительно помогает моему бизнесу процветать!

Давно искал решение для управления магазином и Elbuz превзошел все мои ожидания, интеграция с поставщиками помогли мне значительно увеличить оборот моего бизнеса. Теперь я не могу представить свою работу без Elbuz!

Я была в полной растерянности с управлением моим магазином одежды, пока не начала использовать эту программу, поддержка любых форматов данных и оптимизация цен сделали мою жизнь проще.

Благодаря этой программе всё стало на много проще, она сама обновляет цены и контролирует наличие товаров, теперь могу с уверенностью сказать, что мой магазин летит как ракета!

Аналитика цен помогли мне увеличить прибыль и упростить процесс работы, теперь я могу сосредоточиться на создании уникальных итальянских образов, не теряя времени на рутинные задачи.

Я работаю в индустрии красоты и эта программа стала для меня настоящим спасением. Автоматизация сравнения цен и оптимизация закупок позволяют мне экономить время и деньги.

Использование этой программы действительно изменило игру, сравнение прайсов, аналитика цен и контроль наличия товаров - все это настоящий Game Changer для моего бизнеса!

Я влюблен в эту программу! Сегментация товаров и автоматизация сравнения цен помогают мне максимизировать прибыль. Благодаря Elbuz, мой магазин стал еще более успешным!

Я владелец интернет-магазина для любителей активного отдыха, и этот продукт стал моим надежным партнером, спасибо за такой крутой инструмент!
Владельцы интернет-магазинов, которые стремятся к высоким показателям должны попробовать Elbuz.
Окупаемость инвестиций удивит даже крупных игроков - всего за один месяц вы начнете видеть прибыль, а на второй месяц доход как обычно покрывает затраты на использование Elbuz!
© 2024 Elbuz. Все права защищены.



















